Geerative models with tractable explicit density 值的是$p(x)$可以直接计算出来,包括了大部分auto regressive model (NADE, MADE, PixelRNN/CNN),还包括flow-based model(通过变量替换,用$p(z)$通过变换得到$p(x)$,即$x=T(z)$。
basic trick: 计算雅可比行列式最好优化成三角矩阵 diagonal matrix,because the determinant of a triangular matrix is just the product of the diagonal elements, 因此将原先的$O(D^3)$复杂度降为$O(D)$,能够解决部分计算问题!
Finite compositions model: construct a flow with transformation $T$ by composing a finite number of simple transformations $T_k$. 有限个简单变换$T$构成的flow mode
Autgressive flows
Linear flows
Residual flows
耦合技术 Coupling layers
NICE (Dihn et al. 2015), Real NVP (Dihn et al. 2017), Glow (Kingma and Dhariwal, 2018), WaveGlow (Prenger et al. 2019), FloWaveNet (kim et al. 2019), Flow++ (Ho et al. 2019).
优点:
采用了计算对称性,模型评估和求逆计算的速度快(efficiently)
模型评估和采样可以在一次神经网络传递中进行(allow both density evaluation and sampling to be performed in a single neural network pass)
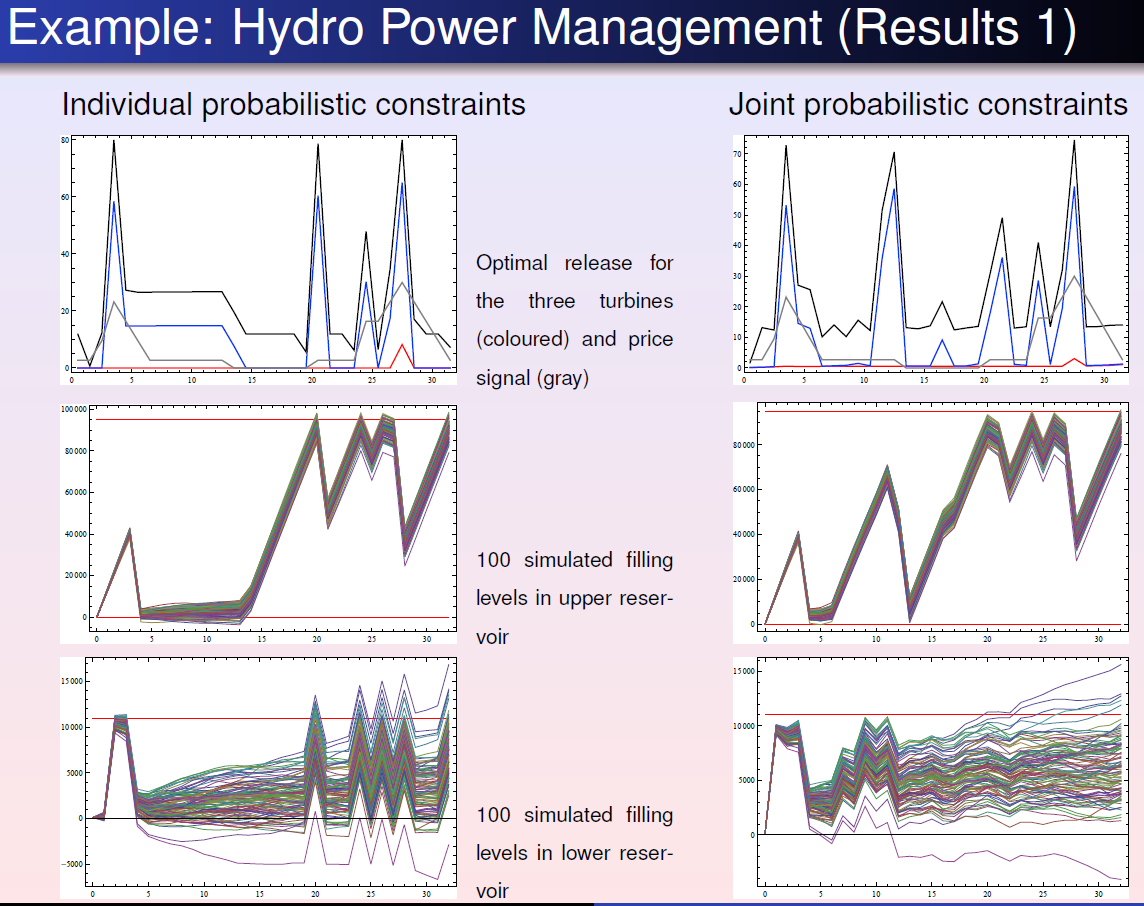
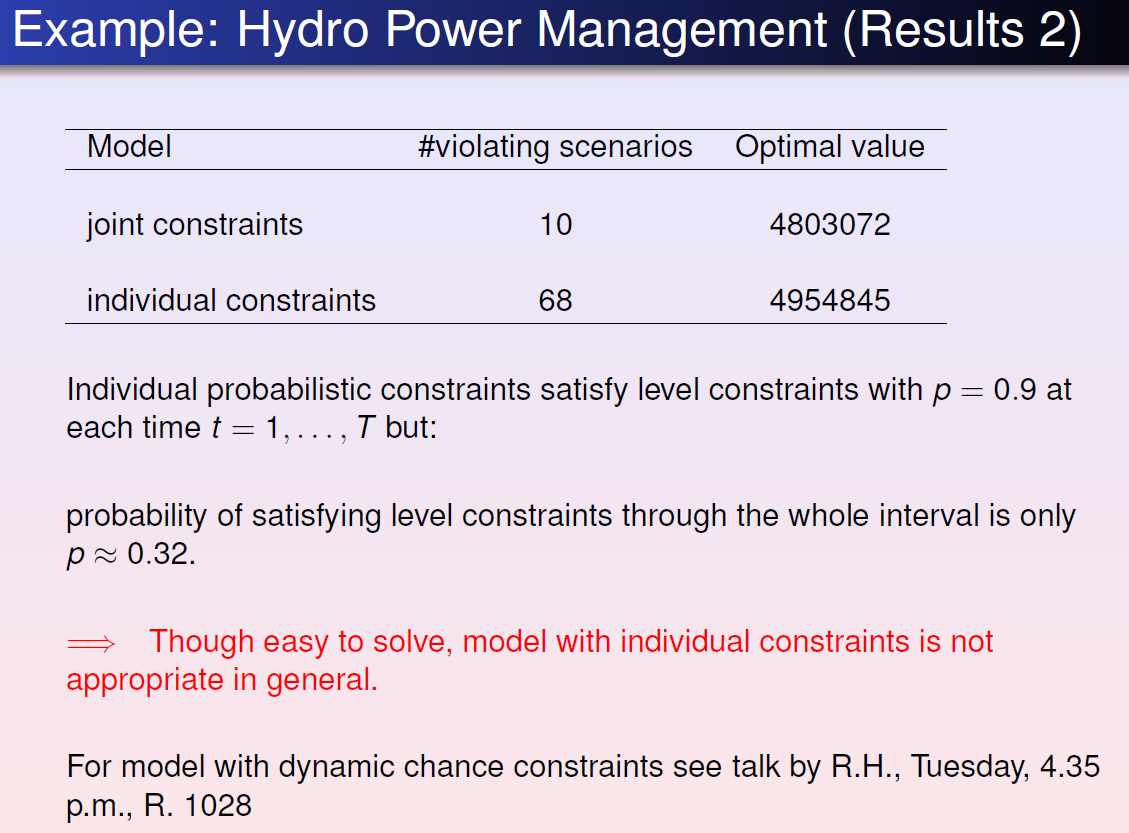
Individual chance constraints are easy to solve, however, they only guarantee that each line satisfies the constraint to a certain confidence level.
Joint chance constraint: $$ h_i(x,\xi) \geq 0 \rightarrow P(h_i(x,\xi) \geq 0 \ (i=1,\cdots, m))\geq p \quad $$ Joint chance constraint ensures that the constraint as a whole is satisfied to a certain confidence level, however, it is incredibly difficult to solve, even numerically.
Solving Method:
Simple case (decision and random variables can be decoupled):
chance constraints can be relaxed into deterministic constraints using probability density functions (pdf). Then, use LP or NLP to solve.
Linear ( $h$ is leaner in $\xi$ ), i.e., $P(h(x)\ge 0)\ge p$
Two types:
separable model: $P(y(x)\ge A\xi)\ge p$
bilinear model: $P(\Xi \cdot x \geq b) \geq p$
calculate the probability by using the probability density function (pdf) and substitute the left hand side of the constraint with a deterministic expression
PDF :
statistical regression (abundant data),
interpolation and extrapolation (few data)
Marginal distribution function (when uncertain variables has correlations)
Feasible region depends on confidence level
high confidence level $\rightarrow$ small feasible region
low confidence level $\rightarrow$ larger feasible region
can make different confidence level with important
Nonlinear
relax problem by transforming into deterministic NLP problem.
Solving nonlinear chance constrained problem is difficult, because nonlinear propogation makes it hard to obtain the distribution if output variables when distribution of uncertainty is unknown.
strategy: back-mapping
robust optimization
sample average approximation
Complex case (decision and random variables interact and cannot decouple)
impossible to solve.
Challenges:
Structural Challenges
Structural Property:
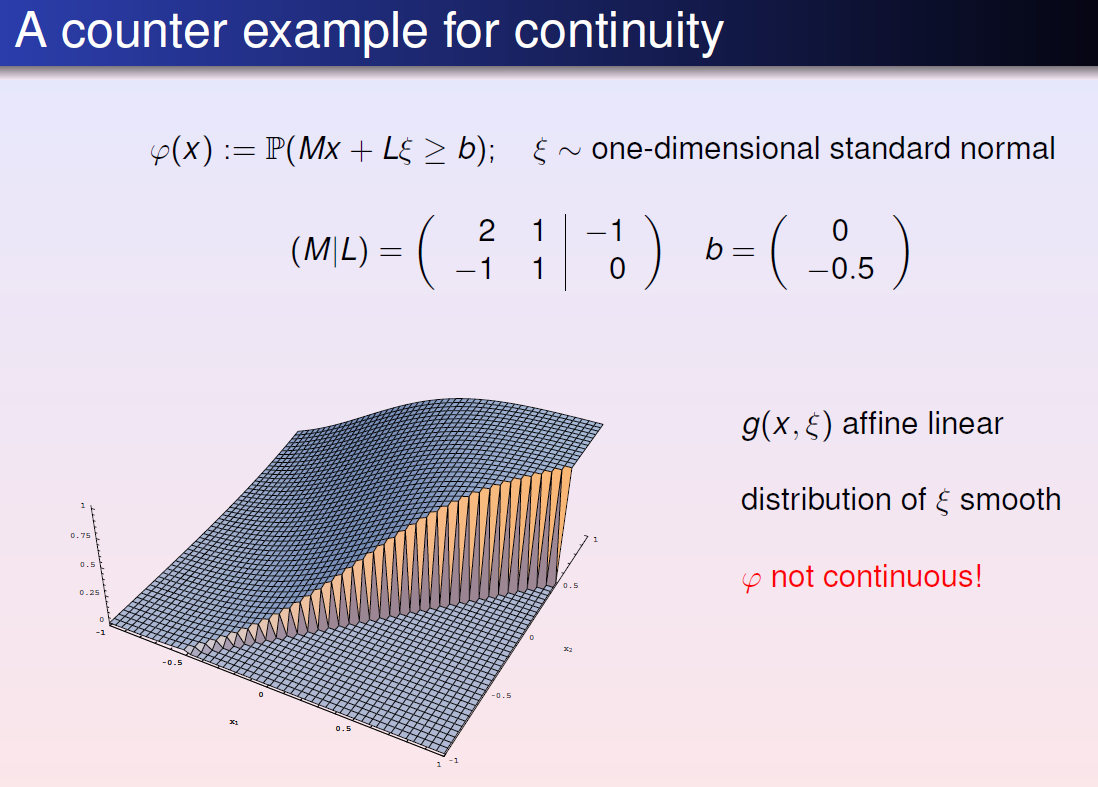
Probability function: $\varphi(x) :=P(h(x, \xi) \geq 0)$
set of feasible decisions: $M :=\left{x \in \mathbb{R}^{n} | \varphi(x) \geq p\right}$
Proposition ====(Upper Semicontinuity, closeness) if $h_i$ are usc, then so is $\varphi$. Then, $M$ is closed
==Proposition== if $h_i$ are continuous, and $P(h_i(x,\xi)=0)=0, \forall x \in R^n \forall i \in {1,\cdots,s}$, then $\phi$ is continuous too.
==Proposition== if $\xi$ has pdf $f_\xi$, i.e., $F_\xi(z)=\int_{-\inf}^{z} f_\xi(x) dx$, then $F_\xi$ is continuous.
==Theorem== (Wang 1985, Romisch/Schultz 1993) If $\xi$ has a density $f_\xi$, then $F_\xi$ is Lipschitz continuous if and only if all marginal densities $f_{\xi_i}$ are essentially bounded.
==Theorem (R.H./R¨omisch 2010)== If $\xi$ has a density $f_\xi$ such that $f^{−1/s}_\xi$ is convex, then $F_\xi$ is Lipschitz continuous
Assumption satisfied by most prominent multivariate distributions: Gaussian, Dirichlet, t, Wishart, Gamma, lognormal, uniform
allows to consider problems with up to a few hundred random variables.
cope with more complicated models, like $\mathbb{P}(h(x) \geq A \xi) \geq p, \quad \mathbb{P}(\Xi \cdot x \geq b) \geq p$:
Compute Derivatives for Gaussian Probabilities of Rectangles
Let $\xi \sim \mathcal{N}(\mu, \Sigma)$ with $\Sigma$ positive definite. Consider a two-sided probabilistic constraint: $\mathbb{P}(\xi \in[a(x), b(x)]) \geq p$. Then, $\alpha_{\xi}(a(x), b(x)) \geq p, \quad$ where $\quad \alpha_{\xi}(a, b) :=\mathbb{P}(\xi \in[a, b])$
Partial derivatives:
Method 1:
Reduction to distribution functions, then use known gradient formula. $$ \alpha_{\xi}(a, b)=\sum\limits_{i_{1}, \ldots, i_{s} \in{0,1}}(-1)^{\left[s+\sum_{j=1}^{s} i_{j}\right]} F_{\xi}\left(y_{i_{1}}, \ldots, y_{i_{s}}\right), \quad y_{i_{j}} :=\left{ \begin{array}{ll} {a_{j}} & {\text { if } i_{j}=0} \ {b_{j}} & {\text { if } i_{j}=1} \end{array} \right. $$ For dimension $s$, there are $2^s$ terms in the sum. Not practicable!
Method 2: $$ \alpha_{\xi}(a, b)=\mathbb{P}\left(\left(\begin{array}{c}{\xi} \ {-\xi}\end{array}\right) \leq\left(\begin{array}{c}{b} \ {-a}\end{array}\right)\right), \quad\left(\begin{array}{c}{\xi} \ {-\xi}\end{array}\right) \sim \mathcal{N}\left(\left(\begin{array}{c}{\mu} \ {-\mu}\end{array}\right),\left(\begin{array}{cc}{\Sigma} & {-\Sigma} \ {-\Sigma} & {\Sigma}\end{array}\right)\right) $$ $\Longrightarrow$ Singular normal distribution, gradient formula not available
==Proposition (Ackooij/R.H./M¨ oller/Zorgati 2010)== Let $\xi \sim \mathcal{N}(\mu, \Sigma)$ with $\Sigma$ positive definite and $f_\xi$ the corresponding density. Then, $\frac{\partial \alpha_{\xi}}{\partial b_{i}}(a, b)=f_{\xi_{i}}\left(b_{i}\right) \alpha_{\tilde{\xi}}\left(b_{i}\right)(\tilde{a}, \tilde{b}) ; \quad \frac{\partial \alpha_{\xi}}{\partial a_{i}}(a, b)=-f_{\xi_{i}}\left(a_{i}\right) \alpha_{\tilde{\xi}}\left(a_{i}\right)(\tilde{a}, \tilde{b})$ with the tilda-quantities defined as in the gradient formula for Gaussian distribution functions.
$\Longrightarrow$ Use Genz’ code to calculate $\alpha_\xi$ and $\nabla_{a, b} \alpha_{\xi}$ at a time.
Derivatives for separated model with Gaussian data:
Let $\xi \sim \mathcal{N}(\mu, \Sigma)$ with $\Sigma$ positive definite and consider the probability function: $$ \beta_{\xi, A}(x) :=\mathbb{P}(A \xi \leq x) $$ If the rows of $A$ are linearly independent, then put $\eta :=A \xi \sim \mathcal{N}\left(A \mu, A \Sigma A^{T}\right)$, then $$ \Longrightarrow \quad \beta_{\xi, A}(x)=F_{\eta}(x)\quad \text{regular Gaussian distribution function} $$ otherwise, $F_\eta$ is a singular Gaussian distribution function (gradient formula not available)
==Theorem (R.H./M¨ oller 2010, see talk by A. M¨ oller, Thursday, 3.20 p.m., R. 1020)== $\frac{\partial \beta_{\xi, A}}{\partial x_{i}}(x)=f_{A_{i} \xi}\left(x_{i}\right) \beta_{\tilde{\xi}, \tilde{A}}(\tilde{x})$ where $\tilde{\xi} \sim \mathcal{N}\left(0, l_{s-1}\right)$ and $\tilde{A}$, $\tilde{x}$ can be calculated explicitly from $A$ and $x$.
use e.g., Deak’s code for calculating normal probabilities of convex sets.
Derivatives for bilinear model with Gaussian data
probability function: $\gamma(x) :=\mathbb{P}(\Xi x \leq a)$ with normally distributed $(m,s)$ coefficient matrix. Let $\xi_i$ be the $i$th row of $\Xi$\
Global optimization: if the optimization problem is convex, the local optimum is global optimum; otherwise, methods such as McCormick Envelope Approximation should be used.
if $F_\xi (h(x) \ge p)$ is concave, the optimization problem is convex.
Sufficient:
components $h_j$ concave: e.g., $h$ is a linear mapping
==Corollary (Convexity in the separable model)== Consider the feasible set $M := {x \in \mathbb{R}^n | P(A\xi \leq h(x)) \geq p}$. Let $\xi$ have a density $f_\xi$ such that $\log f_\xi$ is concave and let the $h_i$ be concave (e.g., $h$ linear). Then, $M$ is convex for any $p\in[0, 1]$.
Bilinear model:
feasible set $M :=\left{x \in \mathbb{R}^{n} | \mathbb{P}(\Xi x \leq a) \geq p\right}$
==Theorem (Van de Panne/Popp, Kataoka 1963, Kan 2002, Lagoa/Sznaier 2005)== Let $\Xi$ have one row only which has an elliptically symmetric or log-concave symmetric distribution (e.g., Gaussian). Then, $M$ is convex for $p\ge 0.5$.
==Theorem (R.H./Strugarek 2008)== Let the rows $\xi_i$ of $\Xi$ be Gaussian according to $\xi_i \sim \mathcal{N}(\mu_i,\Sigma_i)$. If the $\xi_i$ are pairwise independent, then $M$ is convex for $p > \Phi(\max{\sqrt{3},\tao}), where
$\Phi =$ 1-dimensional standard normal distribution function
$\tau=\max {i} \lambda{\max }^{(i)}\left[\lambda_{\min }^{(i)}\right]^{-3 / 2}\left|\mu_{i}\right|$ -$\lambda_{\max }^{(i)}, \lambda_{\min }^{(i)} :=$ largest and smallest eigenvalue of $\Sigma_i$. Moreover, $M$ is compact for $p>\min {i} \Phi\left(\left|\mu{i}\right|{\Sigma{i}^{-1}}\right)$
A challenging issue comes in when the distribution is uniform or normal with independent components, since these may lack strong log concavity in certain circumstances. Furthermore, it should be noted that the Student’s t-distribution, the Cauchy distribution, the Pareto distribution, and the log-normal distribution are not log concave.
Stability Challenges
Distribution of $\xi$ rarely known $\Longrightarrow$ Approximation by some $\eta$ $\Longrightarrow$ Stability?
==Theorem (R.H./W.R¨omisch 2004)==
$f$ convex, $C$ convex, closed, $\xi$ has log-concave density
\Psi(\xi)$ nonempty and bounded
$\exists x \in C : \quad \mathbb{P}(\xi \leq A x)>p$ (Slater point) Then, $\Psi$ is upper semicontinuous at $\xi$: $$ \Psi(\eta) \subseteq \Psi(\xi)+\varepsilon \mathbb{B} \quad \text { for } \quad \sup {z \in \mathbb{R}^{s}}\left|F{\xi}(z)-F_{\eta}(z)\right|<\delta $$ If in addition
$f$ convex-quadratic, $C$ polyhedron,
$\xi$ has strongly log-concave distribution function, then $\Psi$ is locally Hausdorff-Holder continuous at $\xi$:
$$ \left.d_{\text {Haus }}(\psi(\eta), \psi(\xi)) \leq L \sqrt{\sup {z \in \mathbb{R}^{s}}\left|F{\xi}(z)-F_{\eta}(z)\right|} \quad \text { (locally around } \xi\right) $$
pdf is nor precise, most is approximation.
slight changes in distribution may cause major changes to optimum
if assumed distribution is slightly different from actual distribution, not stable.
In order to achieve Hölder- or Lipschitz stability one has to impose further structural conditions, such as strong log-concavity, strict complementarity, and C1,1-differentiability.
Applications
Engineering:
UGV, UAV: Optimal Navigation and Reliable Obstacles Avoidance
System description: $$ \begin{aligned} \dot x & = f(x,u,\xi)\ 0 & = g(x,u,\xi) \end{aligned} $$ $\xi$ may be:
random obstacles
sensor measurement errors
state generated errors
Probability density function of these variables are estimated based on previous data. and formulated into chance constraints.
Based on these constraints, unmanned vehicles can travel through a specific region with the shortest distance while avoiding random obstacles at a high confidence level.2
Power system management:
Risk management
Conclusion
The chance-constraint method is a great way to solve optimization problems due to its robustness. It allows one to set a desired confidence level and take into account trade-off between two or more objectives. However, it can be extremely difficult to solve. Probability density functions are often difficult to formulate, especially for the nonlinear problems. Issues with convexity and stability of these questions mean that small deviations from the actual density function could cause major changes in the optimal solution. Further complications are added when the variables with and without uncertainty can not be decoupled. Due to these complications, there’s no single approach to solving chance-constraint problems. Though the most common approach to simple questions is to transform the chance constraints into deterministic functions by decoupling the variables with and without uncertainty and using probability density functions.
This approach has many applications in the engineering field and the finance field. Namely, it is widely used in energy management, risk management, and more recently, determination of production level, performance of industrial robots, and performance of unmanned vehicle. A lot of research in the area focuses on solving nonlinear dynamic questions with chance constraints.
we already know some common parametric probability distributions $p(x|\theta)$.
Now, we need to know how to learn unknown parameters $\theta$ from given data $\mathcal{D}={x[1],\cdots,x_[N]}$. Then, use these parameters to make prediction.
Learning
Methods to learning the unknown parameters $\theta$ from data
Maximum Likelihood Estimation (MLE)
Given data $\mathcal{D}={x[1],\cdots,x_[N]}$
Assume:
distribution ${p_\theta : \theta \in \Theta}$ where $p(\theta)=p(x|\theta)$
$\mathcal{D}$ is sampled from $X_{1}, X_{2}, \ldots, X_{N} \sim p_{\theta^{}}$ for some $\theta^ \in \Theta$
Random variables $X_{1}, X_{2}, \ldots, X_{N}$ are i.i.d
Goal: estimate $\theta^*$
Method: estimate $\theta_{MLE}$ is a maximum likelihood estimate (MLE) for $\theta^*$ if
Solution: maximize the logarithm $\theta_{MLE}=\underset{\theta}{\operatorname{argmax}}\left[\log\left(\prod_{i=1}^{N} p(x[i] | \theta)\right)\right]$. Then, solve by taking derivative w.r.t. $\theta$ equal to 0.
Advantages:
Easy and fast to compute
Nice Asymptotic properties**:**
Consistent: if data generated from $f(\theta^*)$, MLE converges to its true value, $\hat{\theta}_{MLE} \rightarrow \theta^*$ as $n \rightarrow \infty$
Efficient: there is no consistent estimator that has lower mean squared error than the MLE estimate
Functional Invariance: if $\hat{\theta}$ is the MLE of $\theta^*$, and $g(\theta^*)$is a transformation of $\theta^*$ then the MLE for $\alpha=g(\theta^*)$ is $\hat{\alpha}=g(\hat{\theta})$
Disadvantages:
MLE is a point estimate i.e., does not represent uncertainty over the estimate
MLE may overfit.
MLE does not incorporate prior information.
Asymptotic results are for the limit and assumes model is correct.
MLE may not exist or may not be unique
not know uncertainty of the parameter estimation
Bayesian Approach
To model uncertainty of the parameter estimation
Fitting: Instead of a point estimate $\hat{\theta}$, compute the posterior distribution over all possible parameter values using Bayes’ rule:
$\prod_{i=1}^{N} p(x[i] | \theta) p(\theta)=\prod_{i=1}^{N} \operatorname{Norm}{x[i]}\left[\mu, \sigma^{2}\right] \underbrace{\operatorname{NormlnvGam}{\mu, \sigma^{2}}[\alpha, \beta, \gamma, \delta]}_{\text{conjugate prior}}$ if we use Guassian as our observation model, i.e. $p(x|\theta)$
Properties:
models uncertainty over parameters.
incorporating prior information
can derive quantities of interest, $p(x<10|D)$
can perform model selection.
Drawbacks:
Need Prior
Computationally intractable
If initial belief not conjugate to normal likelihood.. bad
Maximum a Posterior Estimation (MAP)
Given: data $D={x[1], \cdots, x[N]}$
Assume:
joint distribution $p(D,\theta)$
$\theta$ is a random variable
Goal: Choose “good” $\theta$
Method:
estimate $\theta_{MAP}$ is a maximum a posterior (MAP) estimation if
$$\begin{align} \theta_{MAP}&=\underset{\theta}{\operatorname{argmax}} [p(\theta|D)]\ &=\underset{\theta}{\operatorname{argmax}}\left[\frac{p(D|\theta)p(\theta)}{p(D)} \right] \quad \text{Bayes’ rule}\&=\underset{\theta}{\operatorname{argmax}}\left[\frac{\prod_{i=1}^N p(x[i]|\theta)p(\theta)}{p(D)} \right]\quad \text{i.i.d}\ &=\underset{\theta}{\operatorname{argmax}}\left[ \prod_{i=1}^N p(x[i]|\theta)p(\theta) \right] \quad p(D)\ \text{ is removed since it is independent of}\ \theta \ \end{align}$$
Then set $\frac{\part L}{\part \theta_i}=0$ for each parameter $\theta_i$
Properties:
Fast and easy
incorporate prior information
Avoid overfitting (“regularization”) ?
As $n \rightarrow \infty$, MAP tends to look like MLE, but not have same nice asympototic properties.
Drawbacks:
Point estimation (like MLE)
not capture uncertainty over estimates
NEED to choose Prior.
Not functionally invariant:
if $\hat{\theta}$ is the MLE of $\theta^*$, and $g(\theta^*)$ is a transformation of $\theta^*$, then the MAP for $\alpha = g(\theta^*)$ is not necessarily $\hat{\alpha} = g(\hat{\theta})$
Prediction
MLE / MAP: evaluate new data point under parameter learnt by MLE /MAP.
Bayesian: calculate weighted sum of predictions from all possible values of parameters: $$ \begin{aligned} p\left(x^{} | \mathcal{D}\right) &=\frac{p\left(x^{}, D\right)}{p(D)} \quad \text{(conditional probability)} \ &=\frac{\int p\left(x^{}, D, \theta\right) d \theta}{p(D)} \quad \text{(marginal probability)} \ &=\frac{\int p\left(x^{}, \theta | D\right) p(D) d \theta}{p(D)} \quad \text{(conditional probability)} \ &=\int p\left(x^{} | D, \theta\right) p(\theta | D) d \theta \quad \text{(conditional probability)} \ &=\int p\left(x^{} | D\right) p(\theta | D) d \theta \quad \text{(conditional independence)} \end{aligned} $$
Predictive Density
$$ p\left(x^{} | D\right)=\int \underbrace{p\left(x^{} | \theta\right)}{\text{weights}} \underbrace{p(\theta | D) d \theta}{\text{prediction for each possible}\ \theta} $$
Make a prediction that is an infinite weighted sum (integral) of the predictions for each parameter value, where weights are probabilitys.
consider MLE and MAP estimates as probability distributions with zero probability everywhere except at estimate
Training data decrease, Bayesian become less certain, but MAP is wrongly overconfident.
Exponential Family
exponential family:
a set of probability distributions ${p_\theta: \theta \in \Theta}$ with the form $$ p_{\theta}(x)=\frac{h(x) \exp \left[-\eta(\theta)^{\top} s(x)\right]}{Z(\theta)} $$ Where
an exponential family is in its natural (canonical 标准的) form if it is parameterized by its natural parameters $\eta$ : $$ p_{\eta}(x)=p(x | \eta)=\frac{h(x) \exp \left[-\eta^{\top} s(x)\right]}{Z(\eta)} $$ Normaliser: $Z(\eta)$ $$ Z(\eta)=\int h(x) \exp \left[-\eta^{\top} s(x)\right] d x $$ Properties:
has conjugate prior.
fixed number of sufficient statistics that summarize iid data. 指数函数的充分统计量的可以从大量的i.i.d.数据中归结为估计的几个值(即 $s (x)$ )
Posterior predictive distribution always has closed form solution
For any ExpFam: $$ \mathbb{E}[s(x)]=\nabla \log \mathrm{Z}(\eta) $$
通过对$Z(\eta)$求导,容易得到充分统计量$s(x)$的均值,方差和其他性质。
Important Properties:
Many distributions are Exponential Family:
PMF
PDF
• Bernoulli • Binomial
• Categorical/Multinoulli
• Poisson
• Multinomial
• Negative Binomial • Negative Binomial
• Normal • Gamma & Inverse Gamma
• Wishart & Inverse Wishart
• Beta
• Dirichlet
• lognormal
• Exponential
•…
Bayesian Networks
Conditional Independence
Fitting probability models (learning) and predictive density (inference)
BUT just at the case of One random variables, i.e. $p(x|\theta)$
How about joint probability with $N$ random variables?
Problem:
Assume $N$ discrete random variables $x_1, \cdots, x_N$, where $x_i\in{1,\cdots,K}$. $\longrightarrow$ need $O(K^N)$ parameters to represent the joint distribution $p(x_1, \cdots, x_N)$ $\longrightarrow$ hard to infer, need huge amount of data to learn all parameters
If all random variables are independent $\longrightarrow$ $O(NK)$ with $p(x_1,\cdots, x_N|\theta) = \prod_{i=1}^N p(x_i|\theta_i)$ $\longrightarrow$ can infer, smaller data
###Definition:
Two random variables $X_A$ and $X_C$ are conditionally independent given $X_B$, $X_{A} \perp X_{C} | X_{B}$ iff $p\left(x_{A}, x_{C} | x_{B}\right)=p\left(x_{A} | x_{B}\right) p\left(x_{C} | x_{B}\right)$ OR $p\left(x_{A} | x_{B}, x_{C}\right)=p\left(x_{A} | x_{B}\right), \quad \forall X_{B} : p\left(x_{B}\right)>0$, which means learning $X_C$ does not change prediction of $X_A$ once we know the value of $X_B$.
###Meanings:
parameter reduction
let $m_i$ denotes the number of parents of node $X_i$, and each node takes on $K$ values.
conditional probability of $X_i$ use $K^{m_i+1}$ parameters
Sum for all nodes, parameter reduction from $O(K^N)$ to $O(K^{m+1})$, and $m \ll N$
Learning with conditional independence: MLE
represent the joint probability distribution
Taking the logarithm of $p(x|\theta)$ converts the product into sums
find the maximum log-likelihood of each parameter $\theta_i$ . this can be executed seperatively.
$\underset{\theta_1}{\operatorname{argmax} \log p(x|\theta)}$, $\underset{\theta_2}{\operatorname{argmax} \log p(x|\theta)}$, $\cdots$, [other random varibles which independent of $\theta-1$ can be removed.]
Learning with conditional independence: MAP
Similar as MLE: $$ \begin{aligned} \underset{\theta_{i}}{\operatorname{argmax}} \log p(\theta | x) &=\underset{\theta_{i}}{\operatorname{argmax}} \log p(x | \theta) p(\theta) \ &=\underset{\theta_{i}}{\operatorname{argmax}}\left{\log p\left(x_{i} | x_{\pi_{i}}, \theta_{i}\right)+\log p\left(\theta_{i}\right)\right} \end{aligned} $$ where $\theta=\left(\theta_{1}, \ldots, \theta_{M}\right)$
Bayesian Networks
Bayesian Network is a DAG $\mathcal{G}$ (no cycle)
node is variables $X_i$, set of parent nodes $X_{\pi_i}$: all variables that are parents of $X_i$
Topological ordering: if $X_i \rightarrow X_j$, then $i<j$ [not unique]
Path: {path follow the arrows cosidering direction}. V.S. Trail: {path follow the edges without considering the direction}
Ancestors: parents, grand-parents , etc. V.S. Descendants: children, grand-children, etc.
Local Markov assumption :
Each random variable $X_i$ is independent of its non-descendants $X_{nonDesc(X_i)}$ given its parents $X_{\pi_i}$
Precise definition of “blocking” has to be done through the “three canonical 3-node graphs”, and “d-separation”.
Three canonical 3-node graphs:
Head-Tail
if none variables are observed, A and B are not independent $A \notperp B | \emptyset$ $$ p(a, b)=p(a) \sum_{c} p(c | a) p(b | c)=p(a) p(b | a) $$
if C observed, using Bayes’ rule, obtain $A \perp B | C$ $$ \begin{aligned} p(a, b | c) &=\frac{p(a, b, c)}{p(c)} \ &=\frac{p(a) p(c | a) p(b | c)}{p(c)} \ &=p(a | c) p(b | c) \end{aligned} \quad \text { (Bayes rule) } $$
Intuition: past A is independent of future B given present C, $\rightarrow$ simple Markov Chain
Tail-Tail
If none variables are observed, NOT independent, $A \notperp B | \emptyset$
If C observed, obtain $A \perp B | C$ , because
$$ \begin{aligned} p(a, b | c) &=\frac{p(a, b, c)}{p(c)} \ &=p(a | c) p(b | c) \end{aligned} $$
Then,
Head-Head
if none variables observed, we obtain $A \perp B | \emptyset$ because $$ p(a, b)=p(a) p(b) $$
if C observed, we obtain $A \notperp B | C$ , because $$ \begin{aligned} p(a, b | c) &=\frac{p(a, b, c)}{p(c)} \ &=\frac{p(a) p(b) p(c | a, b)}{p(c)} \end{aligned} $$ can not obtain $p(a)p(b)$
“V-structure”.
if C unobserved, “blocks”. If C observed, “unblocks”.
Observation of any descendent node of C “unblocks” the path from A to B.
$A \perp B |C$ if all trails from nodes in A are “Blocked” from nodes in B when all C are observed.
A is d-separated form B by C
Key: Independence:
The arrows on the trail meet either head-to-tail or tail-to-tail at the node, and the node is in the set C, or
The arrows meet head-to-head at the node, and neither the node, nor any of its descendants, is in the set C.
Bayes Ball
it’s a “reachability” algorithm”:
shade the nodes in set $C$ (given nodes)
Place a ball at each of the nodes in set $A$
Let the balls “bounce around” the graph according to the d-separation rules:
if none of the balls reach B, then $A \perp B|C$
Else $A \norperp B|C$
can be implement as a breadth-first search
procedure of algorithm:
given Graph $G$ and sets of nodes $X, Y$, and $Z$
Output True if $X\perp Y | Z$, False otherwise.
2 Phases:
Phase 1: “Find all the unblocked v-structures”
traverse the graph from the leaves to the roots, marking all nodes that are in $Z$ or have descendants in $Z$.
Phase 2: “Traverse all the trails starting from $X$”
apply breadth-first-search, stopping a specific traversal when we hit a blocked node.
If $Y$ is reached during. this traversal, return False. Else, return True.
if prior is laplacian distribution: $p(\mathbb{w}|0,b)=\frac{1}{2b}\exp (-\frac{|w|}{b})$
$\log p(\mathbb{w}|0,b)\propto -\frac{|w|}{b}$ , then, have $\lambda = -\frac{2\sigma_n^2}{b}$ , form $l_1$-norm.
derivative of $l_0$-norm: This is zero (as you pointed out), but only in places where it isn’t interesting. Where it is interesting it’s not differentiable (it has jump discontinuities).
derivative of $l_1$-norm: This norm is not differentiable with respect to a coordinate where that coordinate is zero. Elsewhere, the partial derivatives are just constants, $\pm 1$ depending on the quadrant.
derivative of $l_2$-norm: Usually people use the $l_2$-norm squared so that it’s differentiable even at zero. The gradient of $||x||^2$ is $2x$, but without the square it’s $\frac{x}{||x||}$ (i.e. it just points away from zero). The problem is that it’s not differentiable at zero.
Predictive DGM Model
Naiive Bayes
Model:
Class $c \in{1, \ldots, K}$, and input $\mathbf{x}=\left[x_{1}, x_{2}, \ldots, x_{D}\right]^{\top}$
naiive bayes assume that $p(\mathbf{x} | c)=\prod_{j} p\left(x_{j} | c\right)$. Naive assumption: all features are independent
Filled dots are deterministic parameters. If we have priors, we can make parameters random variables (open circles)
$\Longrightarrow$
Even the assumption for naiive bayes is so strong, it still works well?
Key idea: it works well when the local feature dependencies between the two classes “cancel out”.
##Properties of Bayesian network
Independence-Maps (I-maps)
Theorem:
Let $P$ be a joint distribution over $\mathcal{X}$ and $G$ be a Bayesian Network structure over $\mathcal{X}$. If $P$ factories according to $G$, then the local independence assertation $\mathcal{J}_l(G)\subseteq \mathcal{J(P)}$.
The local Markov independence $\mathcal{J}l(G)$ is the set of all basic conditional independence assertions of the form $\left{X{i} \perp\left(X_{\text { nondesc }\left(x_{i}\right)} \backslash X_{\pi_{i}}\right) | X_{\pi_{i}}\right}$
So, $\left{X_{i} \perp\left(X_{\text { nondesc }\left(x_{i}\right)} \backslash X_{\pi_{i}}\right) | X_{\pi_{i}}\right}$
Global Markov independence:
Definition: the set of all independencies that correspond to d-seperation in graph $G$ is the set of global Markov independencies: $$ \mathcal{J}(G)=\left{(X \perp Y | Z) : \operatorname{dsep}_{\mathrm{G}}(X ; Y | Z)\right} $$
Soundness:
Definition: if a distribution $P$ factorizes according to $G$, then $\mathcal{J}_l(G)\subseteq \mathcal{J(P)}$.
i.e. two nodes are d-separated given $Z$, they are conditionally independent given $Z$.
Completeness:
Definition: $P$ is faithful to $G$ if for any conditional independence $(X \perp Y | Z) \in \mathcal{J}(P)$, then $\operatorname{dsep}_{G}(X ; Y | Z)$.
i.e. any independence can be reflect as a d-separation.
Definition: weak completeness
Definition: almost completeness
How Powerful:
Can find a Bayes network to $G$ represent all conditional independencies for a given $P$?
Minimal I-map: “no redundant edges”
perfect map:
No
Undirected Graphical Models (Markov Random Fields)
##Undirected Graphical Models:
UGM (MRF) or (Markov Network) is graph $\mathcal{G}(\mathcal{V},\mathcal{E})$, set of nodes and set of undirected edges
Parameterization: via factors.
Factor $\varphi(\mathcal{C})$ function map from set of variables to non-negative numbers.
NO trails connect $A$ and $B$ when remove all nodes in $C$.
Local Markov Property
Markov Blanket $\operatorname{mb}(X_s)$: set of nodes that renders a node $X_s$ conditionally independent of all the other nodes: $$ X_{S} \perp \overbrace{\mathcal{V} \backslash\left{\mathrm{mb}\left(X_{S}\right), X_{S}\right}}^{\text{all other nodes in}\ G} | \mathrm{mb}\left(X_{S}\right) $$
Markov blanket in UGM is the set of immediate neighbors
node 和除了本身以及neighbors 的其他node 都 conditionally independent. {due to global Markov property}
Markov Blankets for a node $X_s$ in a DGM is the set of node’s parents, children, and co-parents (other parents of children).
对ppt有疑问, p35
Pairwise Markov Property
two nodes $X_s$ and $X_t$ are conditionally independent given the rest if there is no direct edge between them $$ X_{s} \perp X_{t} | \mathcal{V} \backslash\left{X_{S}, X_{t}\right}, \text { where } \mathcal{E}_{s t}=\emptyset $$ 移除其他nodes后无直接连线
relationship among three properties.
Interrelated.
Global Markov $\Longrightarrow$ local Markov $\Longrightarrow$ Pairwise Markov $\Longrightarrow$ Global Markov
for positive distribution $p(\mathbb{x})>0$, the three Markov properties are equavalent.
Parameterization of MRFs
Aim: obtain a local parameterization of UGMs.
For DGM:
Local conditional probabilities: $p(x_i|x_{\pi_i})$
Joint probability is product of local conditional probabilities: $p\left(x_{1}, \ldots, x_{N}\right)=\prod_{i=1}^{N} p\left(x_{i} | x_{\pi_{i}}\right)$
But for UGM, difficult to obtain conditional probabilities since no topological ordering. So, discard conditional probabilities.
Represent the joint as a product of local functions.
Normalize
Factors NOT represent marginal/conditional distributions
Gibbs distribution
Definition: A distribution $P$ is a Gibbs distribution parameterized by a set of factors ${\varphi_1(\mathcal{C}1), \varphi_2(\mathcal{C}2),\cdots, \varphi_m(\mathcal{C}m)}$, where $$ p\left(x{1}, x{2}, \ldots, x{N}\right)=\frac{1}{Z} \prod_{j=1}^{M} \varphi_{j}\left(\mathcal{C}_{j}\right) $$
Factor:
Two nodes $X_i$ and $X_j$ that are not directly linked in UGM are conditionally independent given all other nodes. [不直接相连的nodes是条件独立的]
$\rightarrow$ Factorization of joint probability that places $X_i$ and $X_j$ in different factors.
All nodes $X_C$ in a maximal clique $C$ in UGM form factor (local function) $\varphi(X_C)$
Clique: a fully connected subset of nodes.
Maximal Clique $C$: cliques that cannot be extended to include additional nodes
Hammersley-Clifford: a positive distribution $p(y)>0$ satisfies the CI properties of undirected graph $\mathcal{H}$ iff $p$ can be represented as a product of factors, one per maimal clique:
where $\mathcal{C}$ is the set of all the maimal liques; $\varphi_C(\cdot)$ is the factor or potential function of clique $c$; $\theta$ is the parameter of factors $\varphi_C(\cdot)$ for $c\in\mathcal{C}$; $Z(\boldsymbol{\theta})$ is the partition function $Z(\boldsymbol{\theta}) \triangleq \sum \prod\limits_{c \in \mathcal{C}} \psi_{c}\left(\mathbf{y}{c} | \boldsymbol{\theta}{c}\right)$.
UGM NOT specify a unique factorization.
Hammersley-Clifford is just one type of factorization.
Pairwise MRF:
parameretization to the edges of the graph, rather than maximal cliques. [每条边作为factor,不考虑maximal clique]
SIMPLE but not general.
Properties:
Independent set; Independence map (I-map);
Soundness
if $P$ is a Gibbs distribution over $H$, then $H$ is an I-map for $P$.
Hammersley-Clifford states that if $H$ is an I-map for $P$, then $P$ is a Gibbs distribution over $H$ (for positive distribution)
Weak completeness
if $X$ and $Y$ are not separated in $H$, then there is some distribution $P$ that factories over $H$ where $X$ and $Y$ are dependent.
How Powerful: ? represent all conditional independencies ?
Perfect map: $\mathcal{J}(G)=\mathcal{J}(P)$
UGM are NOT “richer” or “more powerful” than DGM.
representing Potential (local) function
Log potentials is a linear function of parameters:
$\phi_C(y_C)$ is a feature vector derived from the values of the variables $y_C.$
Then, log probability is $$ \log p(\mathbf{y} | \boldsymbol{\theta})=\sum_{c} \phi_{c}\left(\mathbf{y}{c}\right)^{T} \boldsymbol{\theta}{c}-\log Z(\theta) $$ also called “maximum entropy” or “log-linear” model.
every MRF is an [exponential family](#Exponential Family).
Example of MRF
Model:
Ising and Potts (Depth Map from Stereo Images (Multi) or Binary Image Denosing)
Clamped term: $y$ is fixed to its observed values; Unclamped/contrastive term: $y$ is a free variable.
Unclamped term requires inference in the model, once per gradient step, and this makes UGM learning much slower than DGM.
Gradient of log-likelihood rewrite:
$$ \frac{\partial l}{\partial \theta_{c}}=E_{p_{e m p}}\left[\phi_{c}(y)\right]-E_{p(y | \theta)}\left[\phi_{c}(y)\right] $$
$E_{p_{e m p}}\left[\phi_{c}(y)\right]=\frac{1}{N} \sum_{n=1}^{N} \phi_{c}\left(y_{i}\right)$ : Expected feature vector according to empirical distribution.
$E_{p(y | \theta)}\left[\phi_{c}(y)\right]$ : Expected feature vector according to model’s distribution.
At optimum, gradient =0, i.e. $E_{p(y | \theta)}\left[\phi_{c}(y)\right]=\sum_{y} \phi_{c}(y) p(y | \theta)$. But this equation cannot solve for unknown $\theta$.
Solution: Gradient-based optimizers.
$$ \frac{\partial l}{\partial \theta_{c}}=E_{p_{e m p}}\left[\phi_{c}(y)\right]-E_{p(y | \theta)}\left[\phi_{c}(y)\right] $$
But, when computing $E_{p(y | \theta)}\left[\phi_{c}(y)\right]$ requires sum over all states of $y$ , which is intractable.
Solution: combine approximate inference with gradient-based learning. i.e. Stochastic Maximum Likelihood
Stochastic Maximum Likelihood:
iteratively updates the parameter $\theta_{k+1}$ at the $k$ step using the parameter and gradient from previous step: $$ \theta_{k+1} \leftarrow \theta_{k}-\eta g_{k} $$ where $\eta$ is step size or learning rate, $g_k\approx \frac{\part l}{\part \theta_C}$ is the gradient that can be approximated with Markov Chain Monte Carlo (MCMC), sampling.
where $\phi(\mathbb{x}, y_C)$ is a feature vector derived from the global inputs $X$ and the local set of labels $Y_C$.
Advantages: (compare to generative models)
No need to waste resources, i.e. modelling things that we can always observe.
Focus our attention on modeling what we care about, i.e. the distribution of labels given the data.
We can make the potentials (or factors) of the model be data-dependent.
e.g., in natural language processing problems, we can make the latent labels depend on global properties of the sentence, such as which language it is written in.
Disadvantages:
require labeled training data
learning is slower.
Parameter learning:
Consider CRF in log-linear form: $$ p(\mathbf{y} | \mathbf{x}, \mathbf{w})=\frac{1}{Z(\mathbf{x}, \mathbf{w})} \prod_{c} \exp \left(\mathbf{w}{c}^{T} \phi{c}\left(\mathbf{x}, \mathbf{y}{c}\right)\right) $$ where $\phi{c}\left(\mathrm{x}, y_{c}\right)$ is a feature vector derived from the global inputs $\mathbb{x}$ and the local set of labels $y_c$.
Need inference for every single training case inside each gradient step, which is $O(N)$ times slower than MRF.
Also use MAP to estimate unknown parameter $\underset{w}{\operatorname{argmax}}\left{\sum \log p\left(y_{i} | x_{i}, w\right)+\log p(w)\right}$ by choosing a prior.
Probabilistic inference
calculate $p(X_F|X_E)$ for arbitrary subset $E$ and $F$
Parametrise the policy: $\pi_\theta(s,a)=\mathbb P \left[a|s,\theta\right]$. $$ \nabla_\theta \pi_\theta(s,a) = \pi_\theta(s,a) \frac{\nabla_\theta \pi_\theta(s,a)}{\pi_\theta(s,a)} = \underbrace{\pi_\theta(s,a)}{policy} \underbrace{\nabla_\theta \log \pi_\theta(s,a)}{score\ function} $$
softmax policy: [discrete action space]
weighting actions using linear combination of features $\phi(s,a)^\top\theta$
probability of action is proportional to exponentiated weight $\pi_\theta(s,a) \propto e^{\phi(s,a)^\top \theta}$
The score function is $\nabla_\theta \log \pi_\theta(s,a) = \phi(s,a) - \mathbb E_{\pi_\theta} [\phi(s,\cdot)]$
Gaussian policy: [continuous action space]
mean is linear combination of state feature $\mu(s) = \phi(s)^\top \theta$
variance is fixed $\sigma^2$ or parameterised
policy is Gaussian $a\sim\mathcal N(\mu(s),\sigma^2)$
the score function is $\nabla_\theta \log \pi_\theta(s,a) = \frac{(a-\mu(s))\phi(s)}{\sigma^2}$
缺点:
require full episodes
high gradients variance. $\nabla L \simeq \mathbb E [Q(s,a) \nabla \log \pi(a|s)]$ which is proportional to the discounted reward from the given state.
–> add baseline from $Q$, which can be :
some constant value (mean of the discounted rewards)
moving average of discouted rewards
the value of the state $V(s)$
Exploration. entropy 表征uncertainty。
为避免local optimum,substract entropy from the loss function and punish the entropy to be too certain.
Correlation between samples.
Actor-critic and Variants
Actor-critic
reduce the variance of the gradient (由于很难infinite交互,期望与真实有差异,会带来较大的variance)
Parallel actor-learners have a stabilizing effect on training allowing many methods (DQN, n-step Sarsa, AC) to successfully train NN.
与memory replay不同,A3C允许多个agents独立play on separate environments. Each environment is in CPU.
global optimizer and global actor-critic. each agent interact environments in separate thread. Agents reach terminal state –> gradient descent on global optimizer
Pseudocode:
具体实现:
使用torch的multiprocessing模块来生成多个trainer进程,每个进程里都会有一个player与环境交互并采集样本,定期利用buffer中的数据进行梯度更新。为了保证异步更新的有效性,在main进程里实例化了一个share model (global_actor_critic),并且通过global的optimizer来对异步收集的梯度进行优化。
1 2 3
global_actor_critic = Agent(input_dims=input_dims, n_actions=n_actions, gamma=GAMMA) # global network global_actor_critic.actor_critic.share_memory() # share the global parameters in multiprocessing optimizer = SharedAdam(global_actor_critic.actor_critic.parameters(), lr=lr, betas=(0.92,0.999)) # global optimizer
用旧策略$\pi$的状态分布来代替新策略$\tilde\pi$的状态分布,surrogate loss function is $$ \begin{array}{rCl} L_\pi(\tilde{\pi}) &=& \eta(\pi)+\sum\limits_{s} \rho_(s) \sum\limits_{a} \tilde{\pi}(a \mid s) A^{\pi}(s, a) \end{array} $$ 此时,产生动作$a$是基于新的策略$\tilde\pi$,但新策略$\tilde\pi$的参数$\theta$是未知的,无法应用。
利用重要性采样对动作分布进行处理: $$ \sum_{a} \tilde{\pi}{\theta}\left(a \mid s{n}\right) A_{\theta_{\text {old}}}\left(s_{n}, a\right)=E_{a \sim q}\left[\frac{\tilde{\pi}{\theta}\left(a \mid s{n}\right)}{q\left(a \mid s_{n}\right)} A_{\theta_{\text{old}}}\left(s_{n}, a\right)\right] $$ surrogate loss function变为: $$ \sum_{a} \tilde{\pi}{\theta}\left(a \mid s{n}\right) A_{\theta_{\text {old}}}\left(s_{n}, a\right)=E_{a \sim q}\left[\frac{\tilde{\pi}{\theta}\left(a \mid s{n}\right)}{q\left(a \mid s_{n}\right)} A_{\theta_{\text{old}}}\left(s_{n}, a\right)\right] $$ 比较该surrogate loss function $L_\pi(\tilde\pi)$ 和 $\eta(\tilde\pi)$: $$ \begin{aligned} L_{\pi_{\theta_{o l d}}}\left(\pi_{\theta_{o l d}}\right) &=\eta\left(\pi_{\theta_{o l d}}\right) \ \left.\nabla_{\theta} L_{\pi_{\theta_{o l d}}}\left(\pi_{\theta}\right)\right|{\theta=\theta{o l d}} &=\left.\nabla_{\theta} \eta\left(\pi_{\theta}\right)\right|{\theta=\theta{o l d}} \end{aligned} $$
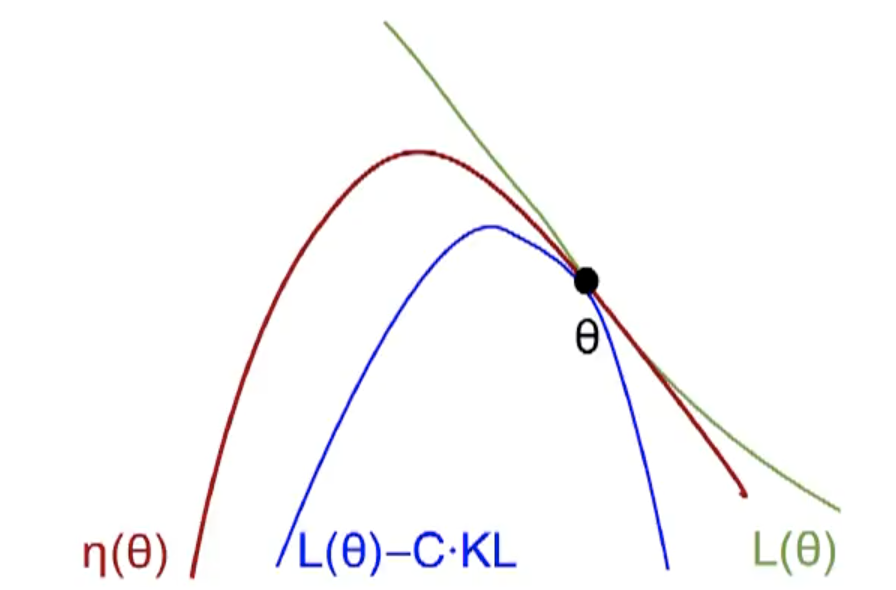
利用不等式:$\eta(\tilde{\pi}) \geq L_{\pi}(\tilde{\pi})-C D_{\mathrm{KL}}^{\max }(\pi, \tilde{\pi})$, where $C=\frac{4 \epsilon \gamma}{(1-\gamma)^{2}}$.
利用惩罚因子$C$, the step size will be small. –> add constraint on the KL divergence (trust region constraint): $$ \begin{array}{l} \underset{\theta}{\operatorname{maximize}} \quad \mathbb{E}{s \sim \rho{\theta_{\text {old}}}, a \sim \pi_{\theta_{old}}}\left[\frac{\pi_{\theta}(a \mid s)}{\pi_{\theta_{old}}(a \mid s)} A_{\theta_{\text {old}}}(s, a)\right] \ \text {subject to} \quad D^{\max}{\mathrm{KL}}\left(\theta{\text {old}}, {\theta}\right) \leq \delta \end{array} $$ 在约束条件中,利用平均KL散度代替最大KL散度。该问题化简为 $$ \begin{array}{l} \underset{\theta}{\operatorname{maximize}} \quad \mathbb{E}{s \sim \rho{\theta_{\text {old }}}, a \sim q}\left[\frac{\pi_{\theta}(a \mid s)}{q(a \mid s)} Q_{\theta_{\text {old }}}(s, a)\right] \ \text { subject to} \quad \mathbb{E}{s \sim \rho{\theta_{\text {old}}}}\left[D_{\mathrm{KL}}\left(\pi_{\theta_{\text {old}}}(\cdot \mid s) | \pi_{\theta}(\cdot \mid s)\right)\right] \leq \delta \end{array} $$ The objective function (surrogate advantage) is a measure of how policy $\pi_\theta$ performs relative to the old policy $\pi_{\theta_{old}}$ using data from the old policy.
接下来就是利用采样得到数据,然后求样本均值,解决优化问题即可。至此,TRPO理论算法完成。
求解优化问题:
The objective and constraint are both zero when $\theta=\theta_{old}$. Furthermore, the gradient of the constraint with respect to $\theta$ is zero when $\theta=\theta_{old}$. TRPO makes some approximations to get an answer quickly. We Taylor expand the objective and constraint to leading order around $\theta_{old}$: $$ \begin{array}{c} \mathcal{L}\left(\theta_{k}, \theta\right) \approx g^{T}\left(\theta-\theta_{k}\right) \ \bar{D}{K L}\left(\theta | \theta{k}\right) \approx \frac{1}{2}\left(\theta-\theta_{k}\right)^{T} H\left(\theta-\theta_{k}\right) \end{array} $$ resulting in an approximate optimization problem, $$ \begin{array}{r} \theta_{k+1}=\arg \max {\theta} g^{T}\left(\theta-\theta{k}\right) \ \text { s.t. } \frac{1}{2}\left(\theta-\theta_{k}\right)^{T} H\left(\theta-\theta_{k}\right) \leq \delta \end{array} $$ This approximate problem can be analytically solved by the methods of Lagrangian duality, yielding the solution: $$ \theta_{k+1}=\theta_{k}+\sqrt{\frac{2 \delta}{g^{T} H^{-1} g}} H^{-1} g $$ A problem is that, due to the approximation errors introduced by the Taylor expansion, this may not satisfy the KL constraint, or actually improve the surrogate advantage. TRPO adds a modification to this update rule: a backtracking line search, $$ \theta_{k+1}=\theta_{k}+\alpha^{j} \sqrt{\frac{2 \delta}{g^{T} H^{-1} g}} H^{-1} g $$ where $\alpha\in (0,1)$ is the backtracking coefficient, and $j$ is the smallest nonnegative integer such that $\pi_\theta$ satisfies the KL constraint and produces a positive surrogate advantage.
Lastly: computing and storing the matrix inverse, $H^{-1}$, is painfully expensive when dealing with neural network policies with thousands or millions of parameters. TRPO sidesteps the issue by using the conjugate gradient algorithm to solve $Hx=g$ for $x=H^{-1}g$ , requiring only a function which can compute the matrix-vector product $Hx$ instead of computing and storing the whole matrix $H$ directly. This is not too hard to do: we set up a symbolic operation to calculate $$ H x=\nabla_{\theta}\left(\left(\nabla_{\theta} \bar{D}{K L}\left(\theta | \theta{k}\right)\right)^{T} x\right) $$ which gives us the correct output without computing the whole matrix.
Over the course of training, the policy typically becomes progressively less random, as the update rule encourages it to exploit rewards that it has already found. This may cause the policy to get trapped in local optima.
PPO
Fundamental Knowledge:
TRPO: $$ \begin{array}{ll} \underset{\theta}{\operatorname{maximize}} & \hat{\mathbb{E}}{t}\left[\frac{\pi{\theta}\left(a_{t} \mid s_{t}\right)}{\pi_{\theta_{\text {old }}}\left(a_{t} \mid s_{t}\right)} \hat{A}{t}\right] \ \text { subject to } & \widehat{\mathbb{E}}{t}\left[\operatorname{KL}\left[\pi_{\theta_{\text {old }}}\left(\cdot \mid s_{t}\right), \pi_{\theta}\left(\cdot \mid s_{t}\right)\right]\right] \leq \delta \end{array} $$ This problem can efficiently be approximately solved using the conjugate gradient algorithm, after making a linear approximation to the objective and a quadratic approximation to the constraint. The theory justifying TRPO actually suggests using a penalty instead of a constraint, i.e., solving the unconstrained optimization problem $$ \underset{\theta}{\operatorname{maximize}} \hat{\mathbb{E}}{t}\left[\frac{\pi{\theta}\left(a_{t} \mid s_{t}\right)}{\pi_{\theta_{\text {old }}}\left(a_{t} \mid s_{t}\right)} \hat{A}{t}-\beta \operatorname{KL}\left[\pi{\theta_{\text {old }}}\left(\cdot \mid s_{t}\right), \pi_{\theta}\left(\cdot \mid s_{t}\right)\right]\right] $$
for some coefficient $\beta$.
a certain surrogate objective (which computes the max KL over states instead of the mean) forms a lower bound (i.e., a pessimistic bound) on the performance of the policy $\pi$.
TRPO uses a hard constraint rather than a penalty because it is hard to choose a single value of $\beta$ that performs well across different problems—or even within a single problem, where the the characteristics change over the course of learning.
Actor-critic:
sensitive to perturbations (small change in parameters of network –> big change of policy space)
In order to address this issue, PPO:
limits update to policy network, and
base the update on the ratio of new policy to old. (make the ratio be confined into a range –> not take big step in parameter space)
Need to account for goodness of state (advantage)
clip the loss function and take lower bound with minimum function
Track a fixed length trajectory of memories (instead of many transitions)
Use multiple network updates per data sample. Use minibatch stochastic gradient ascent
can use multiple parallel CPU
Important Components:
Update Actor is different $$ L^{CPI}(\theta) = \hat{\mathbb E} \left[ \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t) }\hat A_t \right] = \hat{\mathbb E} \left[r_t(\theta) \hat A_t \right] $$
based on ratio of new policy to old policy (can use log)
consider the advantage
Only maximize $L^{CPI}(\theta)$ will lead to large policy update, –> Modify objective
Total loss is sum of clipped actor and critic $$ L_t^{CLIP+VF+S} = \hat{\mathbb E} \left[ L_t^{CLIP}(\theta) - c_1 L_t^{VF} + c_2 S\pi_\theta \right] $$
coefficient $c_1$ of the critic
$S$ term is the entropy term [which is required if the actor and critic are coupled].
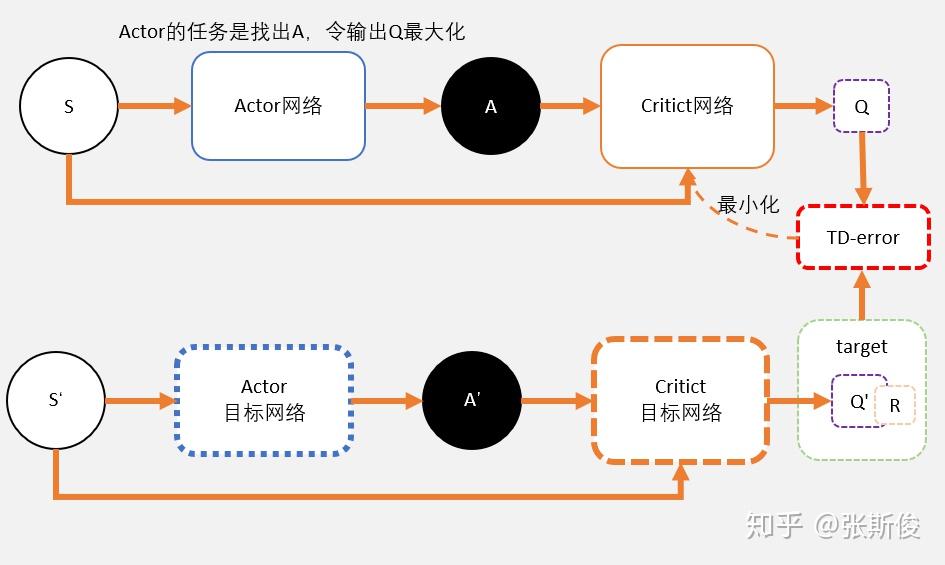
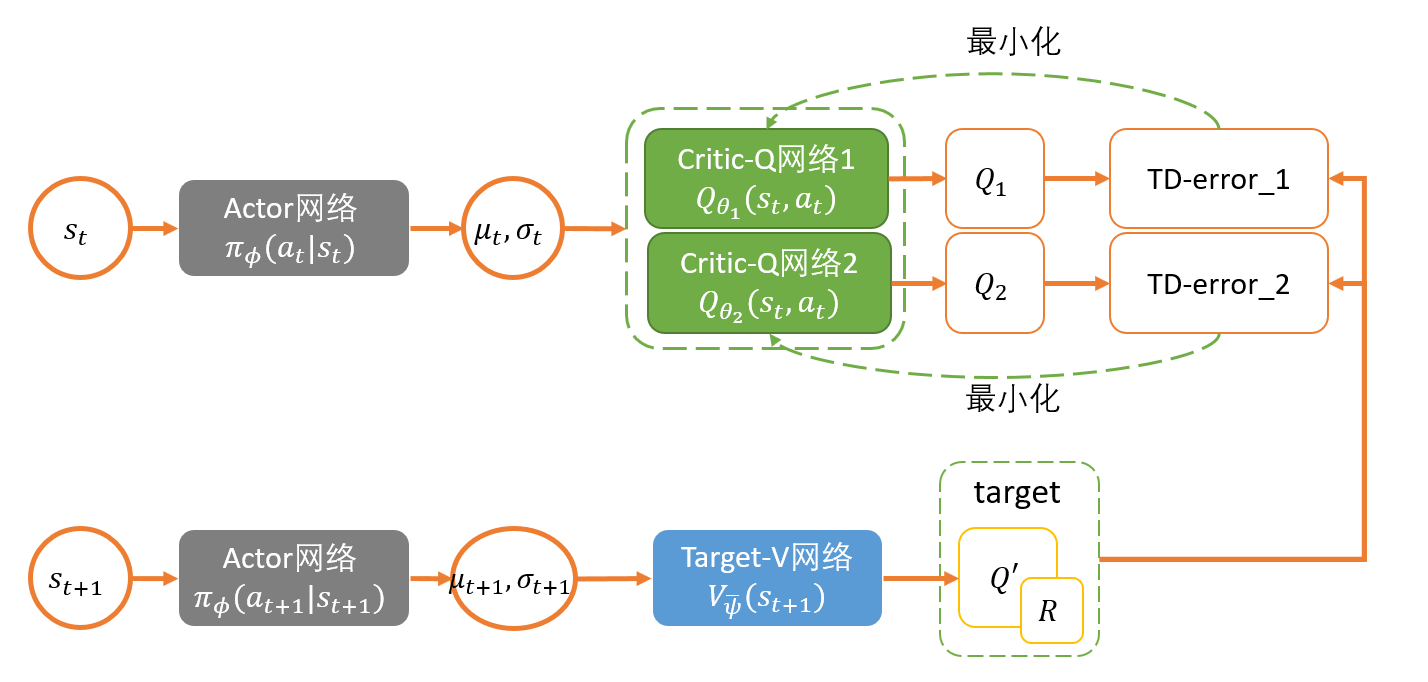
该网络的损失函数就是从critic网络中获取的Q值的平均值,在实现的过程中,需要加入负号,即最小化损失函数,来与深度学习框架保持一致。用数学公式表示其损失函数就是:$L_{actor}=\mathbb E \left[{Q(s,a|\theta^Q)}|_{s=s_t,a=\mu(s_t|\theta^\mu)} \right]$.
Critic:
Input: state $s$ and action $a$
Output: Q value $Q(s,a)$。 【在Actor-Critic方法中,输出的是$V(s)$】
通过最小化目标网络与现有网络之间的均方误差来更新现有网络的参数,
加入experience replay buffer,存储agent与env之间的交互数据。
在实际操作中,如果更新目标在变化,会导致更新困难。–> use “soft” target updates, rather than directly copy the weights –> 方法:添加target actor 和 target critic 网络。并在更新target 网络参数时增加权重$\tau$,即每一步仅采用相对小的权重采用相应训练中的network更新;如此的目的在于尽可能保障训练能够收敛;
Exploration via random process, 为actor采取的action基础上增加一定的随机扰动, 以保障一定的探索完整动作空间的几率。一般的, 相应随机扰动的幅度随着训练的深入而逐步递减;
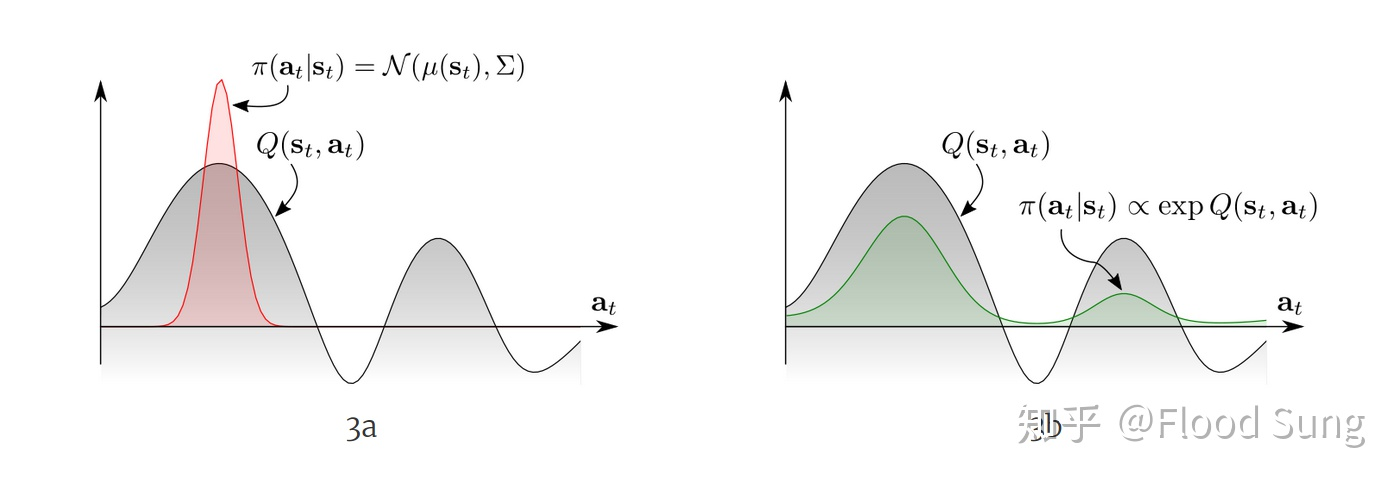
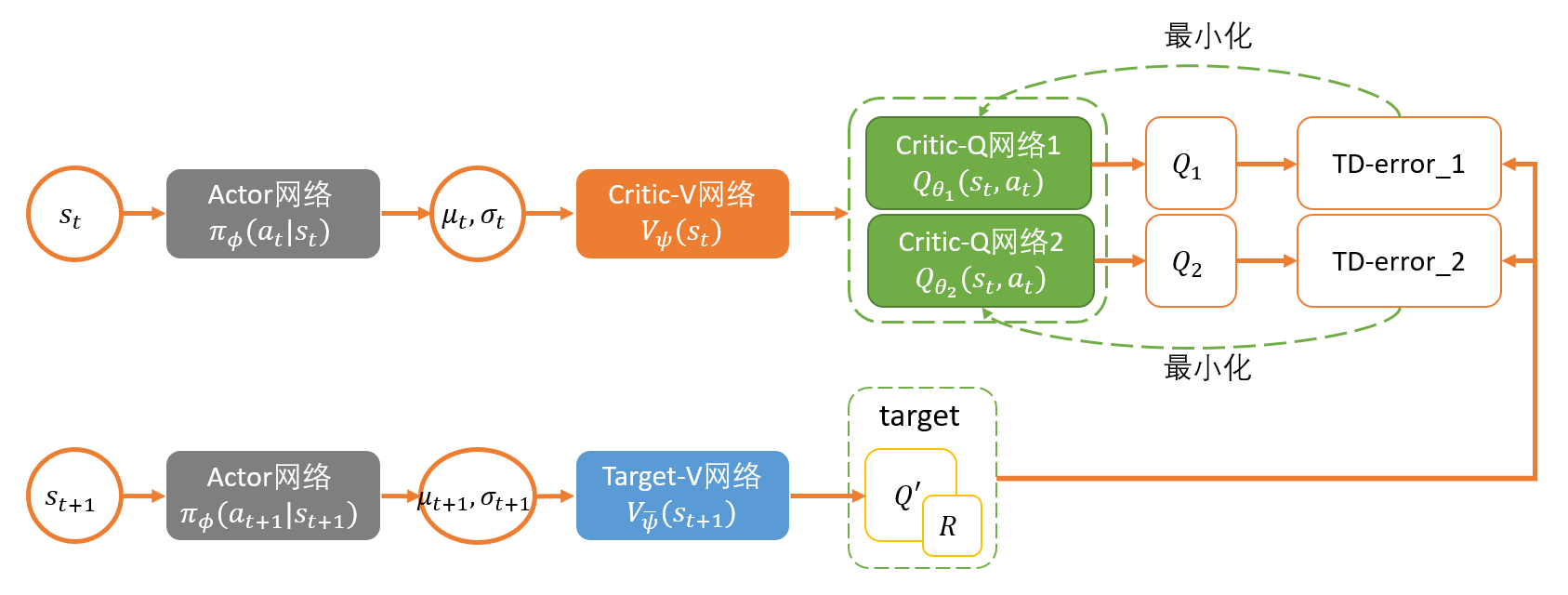
Soft Policy Improvement: 更新policy towards the exponential of new Q-function. Restrict the policy to some set of policies, like Gaussian. $$ \pi^{\prime}=\arg \min {\pi{k} \in \Pi} D_{K L}\left(\pi_{k}\left(\cdot \mid s_{t}\right) \Big| \frac{\exp \left(\frac{1}{\alpha} Q_{\text {soft }}^{\pi}\left(s_{t}, \cdot\right)\right)}{Z_{\text {soft }}^{\pi}\left(s_{t}\right)}\right) $$ 其中, $Z^\pi_{\text{soft}}(s_t)$ 就是是一个配分函数,用于归一化分布,在求导的时候可以直接忽略。此处,通过KL divergence来趋近$\exp(Q_{\text{soft}}^{\pi}(s_t,\cdot))$ ,从而限制policy在一定范围的policies $\Pi$中,从而变得tractable,policy的分布可以是高斯分布。
Value: expected total reward that is obtained from the state. $$ V(s)=\mathbb E \left[ \sum_{t=0}^{\infty} r_t\gamma^t \right] $$ where $r_t$ is the local reward obtained at time $t$ of the episode.
For an agent in state $s_0$, there are N actions to reach states $s_1, s_2, \cdots, s_N$ with rewards $r_1, r_2, \cdots, r_N$. Assume we know the value $V_1, V_2, \cdots, V_N$。 So, $V_0(a=a_i)=r_i+V_i$.
in order to choose the best action, agent needs to calculate the resulting values for every action and choose the maximum possible outcome. $V_0 = \max_{a\in {1, 2,\cdots, N}} (r_a+V_a)$. If we use discount factor $\gamma$, then it becomes $V_0 = \max_{a\in {1, 2,\cdots, N}} (r_a+\gamma V_a)$. So we look at the immediate reward + long-term value of the sate.
For a general cases, the Bellman optimality equation is $$ V_0 = \max_{a\in A} \mathbb E_{s\sim S} \left[r_{s,a}+\gamma V_s\right] = \max_{a\in A} \sum\limits_{s\in S} p_{a,0\rightarrow s} (r_{s,a}+\gamma V_s) $$ where $p_{a,i\rightarrow j}$ is the probability of action a, from state $i$ to state $j$.
Meaning: the optimal value of the state is equal to the action, which gives us the maximum possible expected immediate reward, plus discounted long-term reward for the next state. This definition is recursive: the value of the state is defined via the values of immediate reachable states.
$Q$ for the state $s$ and action $a$ equals the expected immediate reward and the discounted long-term reward of the destination state.
Value of state $V_s$:
$$ V_s = \max_{a\in A} Q_{s,a} $$
The value of a state equals to the value of the maximum action we can execute from this state.
Therefore, we can obtain $$ Q_{s,a} = r_{s,a} + \gamma \max_{a’\in A}Q_{s’,a’} $$
2.2 Value iteration (Q-learning) algorithm
Can numerically calculate the values of states and values of actions of MDPs with known transition probabilities and rewards.
Procedure for values of states:
Initialize values of all states $V_i$ to some initial value (usually zero or random)
For every state $s$ in the MDP, perform the Bellman update $V_s \leftarrow \max_a \sum_{s’} p_{a,s\rightarrow s’} (r_{s,a}+\gamma V_{s’})$
Repeat step 2 for some large number of steps until changes become too small
Procedure for values of actions:
Initialize all $Q_{s,a}$ to zero
For every state $s$ and every action $a$ in this state, perform the update $Q_{s,a} \leftarrow \sum_{s’} p_{a,s\rightarrow s’} (r_{s,a}+\gamma \max_{a’} Q_{s’,a’})$
Repeat step 2 for some large number of steps until changes become too small
Limitations:
state space should be discrete and small to perform multiple iterations over all states. (possible solution: discretization)
rarely know the transition probability for the actions and reward matrix. In Bellman, we need both a reward for every transition and probability of this transition. (solution: use experience as an estimation for both unknowns.)
2.3 Practice
three tables:
Reward table: dictionary
key (state + action + target state)
value: immediate reward
Transition table: dictionary to count the experienced transitions.
Key: state + action,
value: another dictionary mapping the target state into a count of times that we have seen it. 看到target state的频数。
used to estimate the probabilities of transitions. 用来估测 transition probability
Value table: dictionary mapping a state into the calculated value.
Procedure:
play random steps from the environment –> populate the reward and transition tables.
perform a value iteration loop for all states, update value table
paly several full episodes to check the improvement using the updated value table.
Difference from the previous code of value iteration:
Value table. In value iteration, we keep the value of state, so the key in the value table is a state. In Q-learning, Q-function has two parameters: state and action, so the key in the value table is (state, action)
In Q-learning, we do not need the calc-action_value function, since the action value is stored in the value table.
policy is usually represented by probability distribution over available actions.
value-based:
计算每个可能action的value,选择最好的action。
on-policy v.s. off-policy
off-policy: 能够学习old historical data (obtained by a previous version of the agent or recorded by human demonstration or just seen by the same agent several episodes ago)
on-policy: requires fresh data obtained from the environment
1. Cross-Entropy method
Property:
Simple
Good convergence: works well in simple environments (不需要复杂多步policy,有short episodes with frequent rewards).
model-free
policy-based
on-policy
Pipeline of the loop:
pass the observation to the network –> get probability distribution over actions –> random sampling using the distribution –> get action –> obtain next observation
Core of cross-entropy:
舍弃不好的episodes,用好的episodes训练
Steps:
Play N episodes
calculate total reward for each episode, decide on a reward boundary (percentile, e.g., 60th)
throw away all episodes with a reward below the boundary
train on the remaining episodes
repeat
Based on this procedure, neural network can learn how to repeat actions which leads to a larger reward. Then the boundary will be higher.
2. Cross-entropy on CartPole
use one-hidden-layer neural network with ReLU and 128 hidden neurons.
modification: 1) lager batches, 2) add discount factor, 3) keep good episodes for a longer time, 4) decrease learning rate, 5) much longer training time.
4. Theoretical background of cross-entropy
basis of cross-entropy lies in the importance sampling theorem: $$ \mathbb E_{x\sim p(x)} \left[H(x)\right] = \int_x p(x)H(x) dx = \int_x q(x)\frac{p(x)}{q(x)}H(x) dx = \mathbb E_{x\sim q(x)} \left[\frac{p(x)}{q(x)}H(x)\right] $$ In RL, $H(x)$ is a reward value obtained by some policy $x$, and $p(x)$ is the distribution of all possible policies.
首先,replace $H(x)$ with an indicator function. 也就是说function值为1 当reward of this episode 高于threshold;值为0如果reward小于。我们的policy update 就变成了 $$ \pi_{i+1}(a|s)= \operatorname{argmin}{\pi{i+1}} -\mathbb E_{z\sim\pi_{i}(a|s)} \left[R(z)\geq \psi_i\right] \log \pi_{i+1}(a|s) $$ 意思是,用我们现在的policy来sample episodes, 然后minimize the negative log likelihood of the most successful samples and policy.












 $\Longrightarrow$
$\Longrightarrow$ 



 $\Longrightarrow$
$\Longrightarrow$ 





 $$
\begin{aligned} p(y, x | J, \theta) =p(\mathbf{y} | J) \prod_{t} p\left(x_{t} | y_{t}, \boldsymbol{\theta}\right) =\left[\frac{1}{Z(J)} \underbrace{\prod_{s \sim t} \psi\left(y_{s}, y_{t} ; J\right)}_{\text{Pairwise Potential}}\right] \underbrace{\prod_{t} p\left(x_{t} | y_{t}, \theta\right)}_{\text{Unary potential}} \end{aligned}
$$
其实不太懂why
$$
\begin{aligned} p(y, x | J, \theta) =p(\mathbf{y} | J) \prod_{t} p\left(x_{t} | y_{t}, \boldsymbol{\theta}\right) =\left[\frac{1}{Z(J)} \underbrace{\prod_{s \sim t} \psi\left(y_{s}, y_{t} ; J\right)}_{\text{Pairwise Potential}}\right] \underbrace{\prod_{t} p\left(x_{t} | y_{t}, \theta\right)}_{\text{Unary potential}} \end{aligned}
$$
其实不太懂why