3. Convex Analysis
3. Convex Analysis
3.1 Prove convex set:
- $x,y\in C$, then prove $\lambda x + (1-\lambda y) \in C$
- intersection of convex sets are convex
- $f$ is convex $\iff$ epigraph set is convex $f(x)\le \alpha$
3.2 Prove convex function:
- Prove $f(\lambda x + (1-\lambda)y) \le \lambda f(x) + (1-\lambda) y$
- (sum of) linear combination of convex function is convex
- $h$ convex, $g$ non-decreasing convex, $g\circ h$ is convex
- epigraph set is convex $f(x)\le \alpha$ $\iff$ $f$ is convex
- convex, then $x=\sum_{k=1}^k \lambda_jx^{j}$, where $\sum_{j=1}^k \lambda_j =1$, we have $f(x)\le \sum_{k=1}^k \lambda_j f(x^j)$ Jensen’s inequality:
- convex $\iff$ $f(y) \le f(x)+\nabla f(x)^T (y-x)$ Tangent plane characterization:
- convex $\iff$ $\langle \nabla f(\mathbb y)-\nabla f(\mathbb x), \mathbb y - \mathbb x \rangle \ge 0, \quad \forall \mathbb x, \mathbb y \in S$ monotone gradient condition
- convex $\iff$ Hessian is positive semidefinite
For constrained convex programming $\min{f(x)|x\in C}$, $x^*$ is global minimizer $\iff$ $\langle \triangledown f(x^*), x-x^* \rangle > 0, \forall x \in C$.
3.3 Projection: $\Pi_C(z) = \mathrm{argmin} { \frac{1}{2} |x-z|^2 \vert x\in C }$
- $x^* = \Pi_C(z)$ $\iff$ $\langle z-x^*, x-x^* \rangle \leq 0, \forall x\in C$
- $| \Pi_C(z) - \Pi_C(w) | \leq |z-w |$.
- C is linear subspace, $z-x^*\perp C$, then $z = \Pi_C(z) + (z-\Pi_C(z)), \quad \text{and } \quad \langle z-\Pi_C(z), \Pi_C(z)\rangle = 0$
- C is closed convex cone, $\langle z-\Pi_C(z), \Pi_C(z)\rangle = 0$
- If $\theta (x) = \frac{1}{2} | x-\Pi_C(x)|^2$, then $\theta(\cdot)$ is a continuously differentiable convex function and $\nabla \theta(x) = x-\Pi_C(x)$
3.4 Cones:
- Dual cone: $S^* = { y\in S | \langle x,y \rangle \ge 0, \forall x\in S }$. Self-dual cone $C^*=C$, including $\mathbb S_+^n$, $\mathbb R^n$,
- Polar cone: $S^\circ = -S^*$
- $(C^*)^*=C$.
- Spectral cone $\mathcal K^*$, Nuclear-norm cone $\mathcal C$, $\mathrm {COP}_n$, $\mathrm {CPP}_n$, double nonnegative cone $\mathbb D_n$. [Chapter 3, P79]
- $z-\Pi_C(z) = \Pi_{C^\circ}(z)$, if $C$ is closed convex cone.
- Normal cone:
- $N_C(\bar x) = {z\in \mathcal E | \langle z, x-\bar x \rangle \leq 0, \forall x\in C}$ where $\bar x \in C$.
- $u\in N_C(y) \iff y=\Pi_C(y+u)$
- $N_{C_1} (\bar x) + N_{C_2} (\bar x) \subset N_{C_1\cap C_2} (\bar x)$ where $\bar x \in C_1 \cap C_2$.
- $C=\mathcal S^n_+$. $X=U_1D_1U_1^T, D_1 = \mathrm{diag}(d_1, \cdots, d_r)$ with descending order. $N_C(X)={-U_2\Delta U_2^T}$. [P81]
3.5 Subgradient:
$\langle v-u, y-x \rangle \ge 0, \quad \forall u\in \part f(x), v\in \part f(y)$ Monotone mapping
$\part \delta_C(x) = \begin{cases}
\empty \quad & \text{if }x\notin C \
\mathcal N_C(x)= \text{normal cone of $C$ at $x$} \quad & \text{if }x\in C
\end{cases}$ where $C$ is convex subset of $\mathbb R^n$$\part f(0) = { y\in \mathbb R^n | |y|_\infty \le 1 }$, if $f(x) = | x |_1$ [P85]
3.6 Frenchel Conjugate:
$$
f^*(y) = \sup { \langle y,x \rangle - f(x) | x\in \mathcal E }, y\in \mathcal \ E
$$
$f^*$ is always closed and convex, even if $f$ is non-convex or not closed.
Equivalent condition
- $f(x) + f^*(x^*) = \langle x, x^* \rangle$
- $x^* \in \part f(x)$
- $x \in \part f^*(x^*)$
- $\langle x, x^* \rangle - f(x) =\max_{z\in \mathcal E} {\langle z, x^* \rangle - f(z)}$
- $\langle x, x^* \rangle - f^*(x^*) =\max_{z^\in \mathcal E} {\langle x, z^ \rangle - f^*(z^*)}$
- $(f^*)^* = f$
3.7 Moreau-Yosida regularization and proximal mapping
$$
\begin{array}{ll}{\text { MY regularization of } f \text { at } x:} & {M_{f}(x)=\min {y \in \mathcal{E}}\left{\phi(y ; x):=f(y)+\frac{1}{2}|y-x|^{2}\right}} \ {\text { Proximal mapping } f \text { at } x:} & {P{f}(x)=\operatorname{argmin}_{y \in \mathcal{E}}{\phi(y ; x):=f(y)+\frac{1}{2}|y-x|^{2}}}\end{array}
$$
- $x=P_f(x)+P_{f^*}(x), \forall x\in \mathcal E$
- $f(x)=\lambda |x|_1$, $f^*(z)=\delta_C(z)$ where $C=\part f(0)={z\in \mathbb R^n | |z|_\infty \le \lambda }$ [P91]
- If $f=\delta_C$, $P_{\delta_{C}}(x)=\operatorname{argmin}{y \in \mathcal{E}}\left{\delta{C}(y)+\frac{1}{2}|y-x|\right}=\operatorname{argmin}{y \in C} \frac{1}{2}|y-x|^{2}=\Pi{C}(x)$. [P92]
- if $C=\mathbb S_+^n$, Then $\Pi_C(x)=Q\mathrm{diag}d_+ Q^T \quad \text{using spectral decomposition } x=Q \mathrm{diag}dQ^T$
4. Gradient Methods
Descent direction: direction $\mathbf d$ such that $\langle \nabla f(x^*), d\rangle <0 $.
Steepest decent direction: direction $\mathbf d$ such that $\mathbf d^* = - \nabla f(x^*)$.
Steepest descent method with exact line search: + Convergence rate
Accelerated Proximal Gradient method: + Error, complexity
- Sparse regression [P112]
- Projection on to convex cone $\mathrm{DNN}n^* = \mathbb S+^n + \mathcal N^n$ [P112]
Gradient Projection Method:
$x^{k+1} = P_Q(x^k - \alpha_k \nabla f(x^k))$, where $x(\alpha) = x-\alpha \nabla f(x)$, $x_Q(\alpha) = P_!(x(\alpha))$
Stochastic Gradient Descent Method
5. Basic NLP (KKT)
(LICQ): Linear Independency Constraint Qualification : regular point : $\nabla h_i$ and $\nabla g_i$ are linear independent.
KKT necessary condition:
1st order:
$\begin{array}{l}{[1] \quad \nabla f\left(\mathrm{x}^{}\right)+\sum_{i=1}^{m} \lambda_{i}^{} \nabla g_{i}\left(\mathrm{x}^{}\right)+\sum_{j=1}^{p} \mu_{j}^{} \nabla h_{j}\left(\mathrm{x}^{}\right)=0} \ {[2] \quad g_{i}\left(\mathrm{x}^{}\right)=0, \quad \forall i=1,2, \cdots, m} \ {[3] \quad \mu_{j}^{} \geq 0, h_{j}\left(\mathrm{x}^{}\right) \leq 0, \quad \mu_{j}^{} h_{j}\left(\mathrm{x}^{}\right)=0, \quad \forall j=1,2, \cdots, p}\end{array}$
2nd order: $y^T H_L(x^*) y \ge 0$ where $y\in T(x^*)$ tangent plane
- Easier check: $Z(x^*)H_L(x^*)Z(x^*)$ is positive semidefinite
Steps:
- Check regularity condition
- verify KKT first order necessary condition.
- verify KKT second order necessary condition
- Hessian matrix
- basis of null space of $\mathcal D(\mathbb x^*)^T$
- definiteness check
Projection onto simplex: [P139-140]

relax multipliers
KKT sufficient conditions: 1st + 2nd
steps:
- verify it’s KKT point.
- verify it satisfy the second order sufficient condition
- Hessian matrix
- $Z(\mathbf x^*)$
- Determine definiteness
Important points:
KKT point is an optimal solution under convexity, but a global minimizer of a convex program may not be a KKT point.
With regularity condition, a global minimizer is a KKT point. For convex programming problem with at least one inequality constraints, the Slater’s condition ensures that a global minimizer is a KKT point.
slater’s condition: there exists $\hat{\mathbb x} ∈ \mathbb R^n$ such that $g_i(\hat{\mathbb x}) = 0, ∀ i = 1,\cdots, m$ and $h_j(\hat{\mathbb x}) < 0, ∀ j = 1, . . . , p$.
Slater's condition states that the feasible region must have an [interior point](https://en.wikipedia.org/wiki/Interior_(topology)).Linear equality constrained problem:
a point $x^∗ ∈ S$ is a KKT point $\iff$ $x^∗$ is a global minimizer of $f$ on $S$.
No regularity or slater condition is needed.
LInear + convex quadratic programming.

6. Lagrangian duality
optimal value of dual problem is smaller than optimal value of primal problem. Duality gap;
Saddle point optimality $\longleftrightarrow$ KKT
- For a fixed $\mathbb x^∗$, $(λ^∗, μ^∗)$ maximizes $L(\mathbb x^∗, λ, μ)$ over all $(λ, μ)$ with $μ ≥ 0$.
- For a fixed $(λ^∗, μ^∗)$ , $\mathbb{x}^*$ minimizes $L(\mathbb x, λ^∗, μ^∗)$ over all $x ∈ X$.
- saddle point $(\mathbb x^*, \lambda^*,\mu^*)$ $\Rightarrow$ KKT condition. but inverse is not true in general.
- KKT point of a convex program is a saddle point.
7. Nonlinear conic programming


Sparse regression problem:
objective function is convex
APG: [P112]

KKT: [P153-154]


Chapter 7. conic programming
Chapter 8. sPADMM
P214
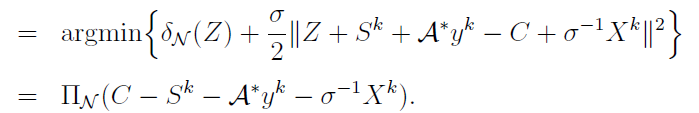
Indicator function:
- Indicator function: $\delta_C(x) = \begin{cases} 0, & x\in C \ \infty, & x\notin C \end{cases}$
$$
\delta_{S_+^n}^* = \delta_{-S_+^n}
$$
$$
\mathrm{Prof}_f(x) = (I+\lambda \part f)^{-1}
$$
$P_f(x) = x-P_{f^*}(x)$
Proximal $P_f$ and Projection $\Pi_C(f(x))$ : When $f=\delta$ indicator function, the two operator are equivalent.
$f(x) = \lambda |x|_1 $, then $f^*(z) = \delta_C(z)$ where $C=\part f(0) = {z\in\mathbb R^n | |z|_\infty \le \lambda }$, the proximal function $P_f(x) = \mathrm {sgn} (x) \circ \max{|x|-\lambda }$ [P91-92]
$f=\delta_C$, $C$ is closed and convex, the proximal and projection operator are equivalent, because $P_{\delta_{C}}(x)=\operatorname{argmin}{y \in \mathcal{E}}\left{\delta{C}(y)+\frac{1}{2}|y-x|\right}=\operatorname{argmin}{y \in C} \frac{1}{2}|y-x|^{2}=\Pi{C}(x)$. When $C=\mathbb S_+^n$, then $\Pi_C(x)=Q \mathrm {diag}(d_+) Q^T$ using spectral decomposition $x=Q\mathrm {diag}(d) Q^T$
$f(x)=|x|_*$, then the $P_f(x) = V\Sigma^+ U^T$.
$x^* = P_f(x^*)$ will converge to the optimum of $f$, i.e., $x^*$.
Dual norm: [P88]
- $f(x)=\lambda |x|1$, then $f^*(x) = \delta{B_\lambda}$, where $B_\lambda = {x\in \mathbb R^n | |x|_\infty\leq \lambda}$.
- $f(x)=\lambda |x|\infty$, then $f^*(x) = \delta{B_\lambda}$, where $B_\lambda = {x\in \mathbb R^n | |x|_1\leq \lambda}$.
- $f(x)=\lambda |x|m$, then $f^*(x) = \delta{B_\lambda}$, where $B_\lambda = {x\in \mathbb R^n | |x|_n\leq \lambda}$, $\frac{1}{m}+\frac{1}{n}=1$, called dual norm.
- $\ell_2$ norm is self-dual norm.
$y\in N_C(x)$, then $y\in \Pi_C(x+y)$
$x=P_f(x)+P_{f^*}(x), \forall x\in \mathcal E$
$G = \Pi_{\mathbb S_+^*}(G) - \Pi_{\mathbb S_+^n}(-G)$
$\min{ \frac{1}{2}|G+Z|^2 | Z\in \mathbb S_+^n} = \frac{1}{2} | G+\Pi_{\mathbb S^n_+}(G)|^2 = \frac{1}{2} |\Pi_{\mathbb S_+^n}(G) |^2$
- $\mathbb x \in S \iff \mathbb x = \mathbb x^* + \mathbb z$ for some $\mathbb z \in \operatorname{Null}(A)$. 【space of x】
- $\mathbb y^T \mathbb z = 0$, $\forall \mathbb z \in \operatorname{Null}(\mathbf A) \iff \exist \lambda^* \in \mathbb R^m$ s.t. $\mathbb y+ \mathbf A^T \lambda^*=0$.
The linear map $\mathcal A(X) = \begin{bmatrix} \langle A_1, X \rangle \ \vdots \ \langle A_m, X \rangle \end{bmatrix}$. Let $\mathcal A^* $ be adjoint of $\mathcal A$ as $\mathcal A^* y = \sum\limits_{k=1}^m y_kA_k, y\in \mathbb R^m$.
$$
\langle \mathcal A^* y, X \rangle = \langle y, \mathcal A X \rangle
$$
if $\mathcal A(X) = \operatorname{diag} (X)$, then $A_k = E_{kk}$, and $\mathcal A^* y = \operatorname{diag} (y)$.
Dual problems:
Linear programs + dual problem:


Quadratic program + dual problem

Square function + Linear inequality constraints [P177]

NLP + dual problem [P178,180]


SDP + Dual Problem [P178, P180]


SDPLS + dual problem [P179, ]




Quadratic Semidefinite problem + Dual problem

Convex quadratic composite optimization problem + dual problem:

d